Diplomacy
|
Home > Diplomacy > Tournaments > Tournament4
Tournaments for AI in the Game of Diplomacy: Tournament #4
Tournament #4 finished on 28 November 2005. It was run in exactly the same way as in Tournament #3, except that the the probability of a given bot being assigned to a given power in a given game was made proportional to the bot's current moving average of Tenacity (rather than Strength), and the Server was set to terminate games after the number of supply centres owned by each bot had remained unchanged for 4 (rather than 1) years. See Bots for details for the players.
The termination criterion (-kill argument) was increased to help increase the average number of players that were eliminated, to increase the discrimination power of each game. (A preliminary test with -kill = 1 indicated that an increase would be useful, and -kill = 4, say, seemed normally to cause about as many players to be eliminated as would be likely for higher values, yet did not extend playing times intolerably.)
The use of Tenacity, rather than Strength, this time was to compare their effectiveness in discriminating players abilities. Also, Tenacity, which measures ability to survive, is important in tournaments where scoring is not just based on having the maximum numbers of supply centres (outright wins or otherwise).
Otherwise, the motivation was the same as in Tournament #3.
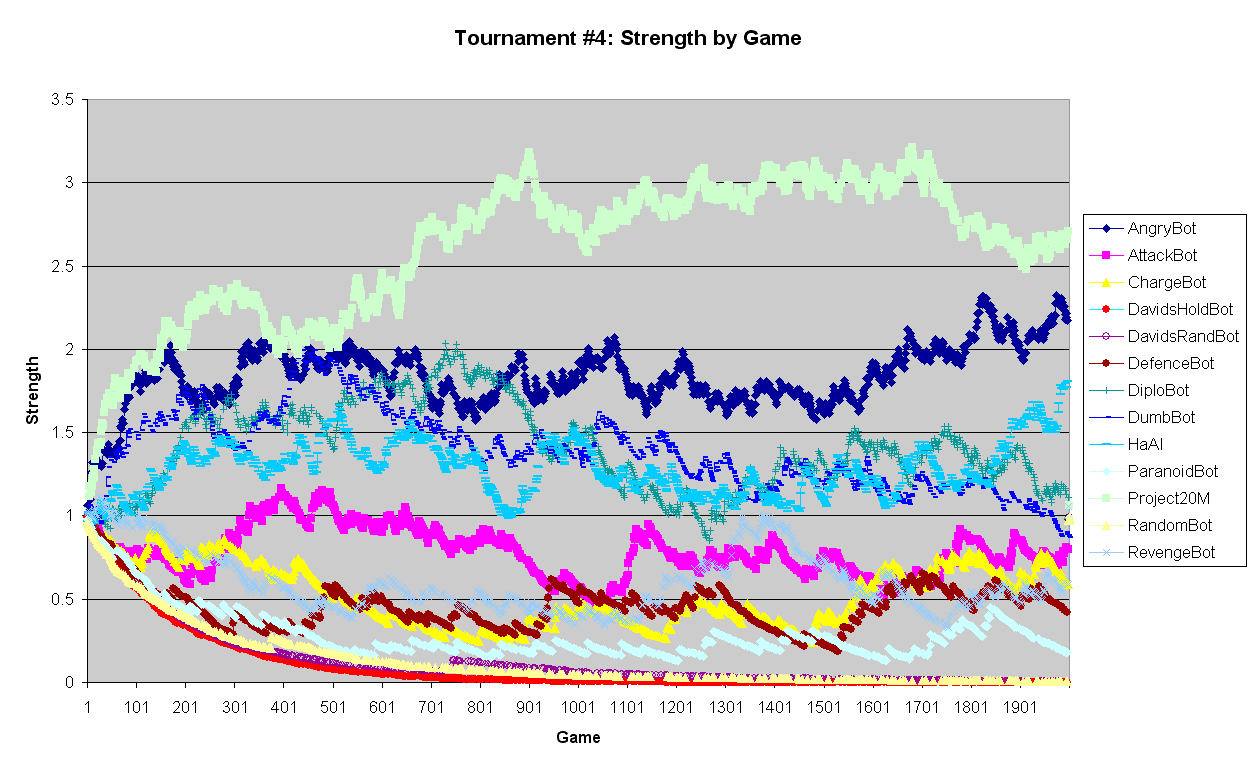
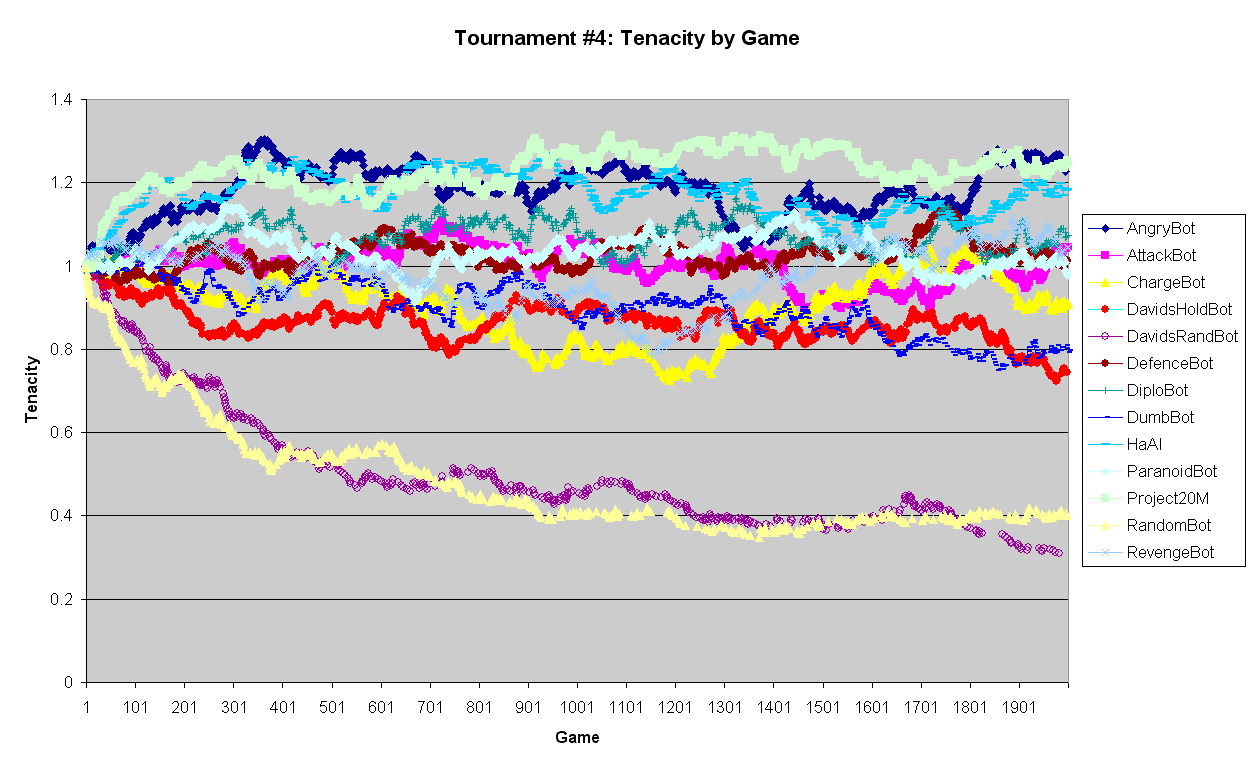
See graphs in Tournament #4: Strength by Game and Tournament #4: Tenacity by Game. For an easy overall comparison, see the four graphs from both Tournaments #3 and #4 click on any graph there for an expanded view. In the key, the same symbol assignments are used; the word Man'chi and version numbers have been omitted; RandomBot means Man'chi RandBot. Symbols for all bots are visible at least in parts of all the above graphs if viewed at full resolution the less obvious ones are near the bottom. Note that the graph range for Strength is over twice that for Tenacity. The style is intended to show the general trends and variability, rather than precise values.
The following tables show various statistics more precisely: Tables 1a-d for Strength and 2a-d for Tenacity; (a) Last, (b) Average, (c) Minimum, (d) Maximum. (All the values before the first game were exactly 1, but this is excluded from the statistics.)
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Although there are significant difference between some aspects of these Results and the Results of Tournament #3, the general Conclusions of Tournament #3 are also applicable here and are not reiterated.
The Strength graphs in Tournaments #3 and #4 are fairly similar, except that there in #4 the trends are less consistently downward; towards the end the second and third rankers seem to be rising at the expense of the leader. There are also differences in rankings of some close bots. There may be extra freedom to drift about in #4 since choice depended on Tenacity, rather than Strength a different measure and one that is not so sharply discriminating.
The Tenacity graphs in Tournaments #3 and #4 are more similar than those for Strength, but once again with difference in rankings of some close bots. It is interesting to compare the graphs for David'sHoldbot; for example. In #3 it is in the middle of the main bunch, so, relatively, it is reasonably tenacious (albeit not victorious) when Strength is being selected for. But in #4 it is near the bottom of the main bunch, so, relatively, most of the other bots are more tenacious when Tenacity being selected for. Note also that it has fewer samples (red dots) near the end in #3, because its rate of being chosen to play is lower, due to its low Strength; this does not happen in #4 as its Tenacity level is always reasonably high.
The Tenacity Tables (2a to d) are comparable to those in Tournament #3. There was a little reordering where values were close (this time, Man'chi AngryBot even lead, ahead of Project20M, in the Last and Min Tables). As might be expected, Strength still showed wider separation between bots than Tenacity, even though Tenacity was now used to control choice of bots in each assignment.
Perhaps unexpectedly, since Strength was was not now used to control choice of bots, the Strength tables (1a to d) show a wider range of values than previously, even ignoring the two exceptionally poor random bots. This is probably because, this time, all bots competed in more nearly equal proportions, since all are generally more similar Tenacity than Strength. So the weaker bots were forced to compete more often, and usually lose, as always, against stronger ones; stronger ones competed a less often but tended to win a higher proportion, as they had weaker competitors on average. However, although using Tenacity rather than Strength when choosing players, paradoxically, produces a bigger discrimination between their Strengths, such discrimination would normally be misleading, since the distribution of bots used would not normally match that in a serious tournament that they may later compete in (if scoring were based on Strength, or similar, rather than Tenacity).
Comparing Strength, rather than Tenacity (whichever is used to control choice of bots) clearly gives a sharper measure of each bot's relative ability (except for the extreme cases of the two random bots), so Strength is probably better for most purposes. However, Tenacity would be better when evaluating for, or training for, future tournaments where the scoring system gives most weight to surviving. But in general, if evaluating for, or training for, future play with a given scoring system, using that exact system as the moving average measure during evaluation or training would, presumably, be the best of all (whether or not using Slow Knockout).
{kind=link}
{kind=link}